Understanding P4
Over the past few months, I’ve had the pleasure of interacting with Rahul Hada, on the topic of the evolving network space. With the recent acquisition1 of the Open Networking Foundation’s projects by the Linux Foundation, a common topic that we pondered about was “will P4 technology finally pick up pace?”
Speculation is fun but there haven’t been very many moves presented to the public’s eyes. So, I’m just waiting on developments now to predict where the next generation of networks is headed towards. However, after wasting a decent bit of my time, I have safely concluded that it’s not very fruitful to theorize when I don’t have much experience working with the technology.
So, this is a guide on understanding P4, possibly comprehend the actual utility of the language, and get better at speculation.
What is P4? #
P4, which stands for Programming Protocol-independent Packet Processors, is a DSL created to handle data plane level network management in routers and switches.
From what I’ve gathered2, P4 differs from OpenFlow in that P4 addresses the need to standardize programming the data plane (i.e. the hash tables in Ethernet address lookup, prefix matching for IPv4, and other stuff). P4 attempts to standardize the approach to populate the forwarding tables so that it doesn’t have to be vendor-specific anymore. P4, seems to me, as a precursor to enable SDN.
OpenFlow doesn’t really control the switch behavior; it gives us a way to populate a set of well-known tables.
So, OpenFlow is the program and P4 is the language. P4 is a means to standardize the language used to perform operations on every single type of switch. OpenFlow, on the other hand, controls these programmed switches to distribute the workload and drive network programmability at the control plane layer.
I guess the foundation being standardized and specific is what the aim is. After all, if your foundation itself is shaky, then it’s not a sustainable effort to produce technology on top of it.
How does it work? #
While I attempt to be correct in my understanding, I understand that I may get some aspects of the technology wrong in my explanation. Thus, here’s the link to the language specification3. I would personally recommend reading through it in case you find some aspects of the system not matching up to my ramblings.
The P4 architecture is a contract between the program and the target. And, this also means that the manufacturer themselves have to provide the support for the P4 compiler and the architecture definition for their target/switch. This will ensure that there is uniformity between programmability in switches across vendors.
In other words, a single P4 program will work on any switch provided that the manufacturer has a P4 compiler coupled with their switch architecture and has followed the architecture model as given. This does mean that the P4 program will not work if the component doesn’t exist.
Consider the case where a switch doesn’t have an expected custom register. In this case, the program that expects a register to exist in the switch fails. Cases like this can be avoided if the architecture mentioned is implemented as expected to run P4 programs on top of it.
In the end, an attempt at uniformity for P4 programs with the same architecture, lays a solid foundation for data plane programmability and reproducibility in academic and industrial scenarios. Which is invaluable to help prevent failures and improve extensibility for engineers in the long run.
The P4 Processing Architecture #
Over the last year, I’ve come to find that most data processing can be visualized as an ETL. To my fortune, one of these cases is P4. A very simple packet processing application can be noted from the image I drew below.
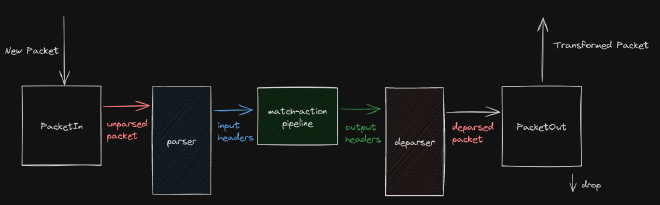
The packet processing architecture has three major sections.
- The Parser
- The Match-Action Pipeline
- The Deparser
NOTE: The definition for the P4 program is provided by the manufacturer.4
While this is out of the scope of this post, it’s important to note that this definition that is provided by the manufacturer of the chip provides the constants, types and other attributes that the chip can use for its processing.
The implementation of the P4 functionality is left to the developer, who can work with the manufacturer-provided definition to build the P4 parsing functionality.
The P4 program itself is boilerplated with the function calls for the parsers, match-action pipeline and the deparser. A generic P4 program will look like this,
/* -*- P4_16 -*- */
#include <core.p4>
#include <v1model.p4>
// <headers>
parser MyParser(...) {...}
control MyLogicOne(...) {...}
control MyLogicTwo(...) {...}
control MyDeparser(...) {...}
V1Switch(
MyParser(),
MyLogicOne(),
MyLogicTwo(),
MyDeparser()
) main;
We direct the flow of operations through the block at the bottom that calls the different phases in P4.
1. The Parser #
When we initially receive a packet from the computer/network interface, we cannot directly utilize it.
We’ll first need to parse the packet for the headers in the packet, which is what we really want to work with. All the information about the data packet, where it’s headed, what type of contents it’s carrying and metadata for the data packet are present in the header.
Once we get the header, we’re off to the match action pipeline phase.
Code #
The code that we are referencing is from the P4-Learning repository by ETH Zurich.5
The parser phase relies on the usage of states. These are essentially
different parsing blocks to validate/accept the incoming packet for further
processing. One could consider this to be a pre processing layer that
accepts/rejects your raw data based on a number of conditions.
In the below example, we’re not really doing much analysis on the packet and are straight up accepting it (thus, allowing it to move to the next phase) after extracting the ethernet header from it.
// Function definition for the parser where we mention that we'll be taking in
// the packet, headers, and metadata.
parser MyParser(packet_in packet,
out headers hdr,
inout metadata meta,
inout standard_metadata_t standard_metadata) {
// The start state is the entrypoint for the packet parsing logic.
// The state machine takes it's inputs from here.
state start{
// Here, we extract the ethernet from the packet's headers. Note that
// we'll need to reconstruct the packet again with the header in the
// deparsing stage.
packet.extract(hdr.ethernet);
// Accept the packet to move onto the next stage here.
transition accept;
}
}
If we really wanted to match up and reject a packet based on some scenario, we’d add that functionality into the code like so,
const bit<16> TYPE_IPV4 = 0x800;
const bit<16> TYPE_IPV6 = 0x86DD;
parser MyParser(packet_in packet,
out headers hdr,
inout metadata meta,
inout standard_metadata_t standard_metadata) {
state start {
packet.extract(hdr.ethernet);
// based on the type of ethernet, we select the state that we wish
// to direct it to. In this case, if it's an ipv4 packet, we'll send
// it over to the ipv4 state.
transition select(hdr.ethernet.etherType){
TYPE_IPV4: ipv4;
TYPE_IPV6: ipv6;
default: accept;
}
}
// The ipv4 state extracts the ipv4 header from the packet and accepts
// the packet.
state ipv4 {
packet.extract(hdr.ipv4);
transition accept;
}
// Reject the packet if it's an ipv6 packet.
state ipv6 {
transition reject;
}
}
2. The Match-Action Pipeline #
This phase is where we’ve already parsed the header content from the packet that we’ve received. Based on the information we’ve gotten, we can perform a simple switch case on the packet and filter out whether or not we wish to forward/drop the packet.
Once we’ve figured that out, we update the headers or leave them be and send it over to the deparser.
Taking an example of ETHZ’s P4 reflector5, let’s go about populating our
MyLogicOne() and MyLogicTwo() phases for processing.
Let’s say that we don’t really want our MyLogicOne phase to do anything. We just want to pipe the packet through. This can be done by putting down the following.
control MyLogicOne(inout headers hdr, inout metadata meta) {
apply { }
}
Now, let’s actually have some logic in MyLogicTwo. This is a process that
swaps the source and destination ethernet addresses to reflect the packet back
to the source host.
control MyLogicTwo(inout headers hdr,
inout metadata meta,
inout standard_metadata_t standard_metadata) {
action swap_mac(){
macAddr_t tmp;
tmp = hdr.ethernet.srcAddr;
hdr.ethernet.srcAddr = hdr.ethernet.dstAddr;
hdr.ethernet.dstAddr = tmp;
}
apply {
// Swap MAC addresses.
swap_mac();
// Set Output port == Input port
standard_metadata.egress_spec = standard_metadata.ingress_port;
}
}
This would essentially be the transformation phase where we’re manipulating the generic flow of the packet. This is where packet categorization and checking takes place for any P4 program.
3. The Deparser #
This phase is used to deparse the packet for further consumption downstream by the actual destination address that the packet was meant for. We deparse the packet so that the destination receives the packet back in the form that they expect.
control MyDeparser(packet_out packet, in headers hdr) {
apply {
// parsed headers have to be added again into the packet
packet.emit(hdr.ethernet);
}
}
Adding the ethernet header back into the packet once the packet has been processed.
That’s it? #
That’s surprisingly all it was?
P4 seems much easier to understand now considering that I’ve finished this blog post. Perhaps it was the white papers I went through or maybe I just spent enough time on the topic.
Anyway, hope that this helped out whoever was reading through this. For any more substantial information, I’d recommend reading through the white papers or working through the P4-Learning Repository.