Designing a Data Pipeline
Preface #
My work at Pune comprised of designing and developing a data migration framework to cater to our data engineering team’s requirements. We had a lot of SQL developers but only a primitive framework to manage the pipelines that they built.
To be fair, the previous pipeline was spun up by my team lead in the span of a week. He got stuff running but didn’t feel like it was good enough for a foundational data migration framework for the company. He would be right, the pipeline that me and the team built up the rest of the year became that very framework that he envisioned.
We designed DRIFT. What started out as a simple csv to db pipeline project grew to become a robust data migration framework. It consisted of data migration, notification management, data delivery, data transformation, and a whole bunch of other systems that provided data cleaning and manipulation.
Inspired by DRIFT, I wish to materialize Flick.
Flick is intended to be a practical foundation for building data migration frameworks. Understanding the Flick architecture will allow one to build their own simple, performant, extensible framework that lets you flick data between storage systems.
Objectively, it may even help you understand what challenges data engineers face on a day-to-day basis! While it may not be the whole and complete truth since each company has their own data migration/management system with their own challenges that require custom solutions, Flick will cater to most common requirements out there to build a sound architecture that makes sense.
The requirements of a data migration architecture #
In most data migration frameworks, you have a few mandatory components. The next few subsections will explain these components and how they’ll be integrating into Flick.
Sources #
A source is a place where the data is retrieved from. It can have structured,
semi-structured, and unstructured data in it too. Depending on the source, the
data in it changes, and that’s okay.
Flick will be designed to read from the source based on the job configuration. It’s our framework’s job to handle the data that’s provided to us after all. Separating the source and the job configuration allows us to keep the source connection interface static while altering the job configuration based on the business requirement.
For the time being, don’t think too much about what the interfaces in the
image are. We’ll cover that in the next section.
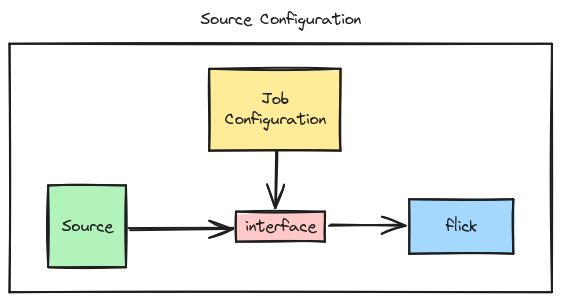
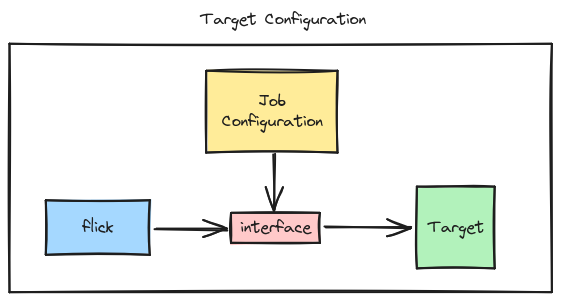
Targets #
A target is the place where the data is to be sent to. The data that is to
be put on the target is defined by the type of target it is, and through the
target section in the job configuration.
Our framework should read the target configuration and ensure that the data is set in a format such that it can be accepted by the target.
Job Configuration #
The job configuration, or hereby referred to as the jobconf, is the file
that contains the settings for the job to execute. It presently should contain
information on which source to retrieve from and which target to output to.
Aside from just the bare minimum, the jobconf also contains the options/flags to be turned on for the particular job execution. The overall architecture now should look something like this,
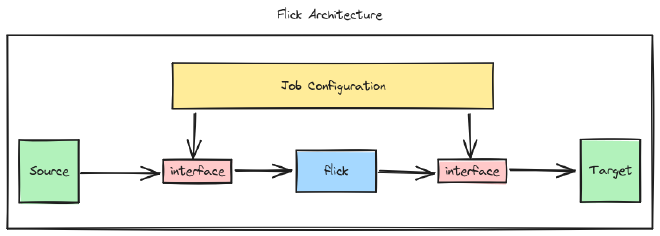
Over the course of the framework’s development, we’ll be able to even transform the data retrieved from the source into the desired format. This will be done using
Transformers. This is not the Transformer that people refer to in Machine Learning. Instead, it’s an interface to a OLAP Database that we can use to manipulate the source data.
Flick Interfaces #
Interfaces in Flick are essentially blocks of code that know how to connect to
and work with the source and/or target API. For example, interacting with the
postgres database would require a client. A postgres interface is that client.
If you’re coming from python, assume that I’m basically talking about the psycopg2 library. Since we’re working with Rust, we’ll be going with the sqlx crate1.
Note that later down the line, we’ll be supporting r/w operations for most interfaces. So, we do not need to segregate between source and target when referring to interfaces. Instead, we’ll have a one-to-one relation for interface to data source/target.
So, in a scenario where we are dealing with a postgres source and a postgres target, it’ll look something like this.
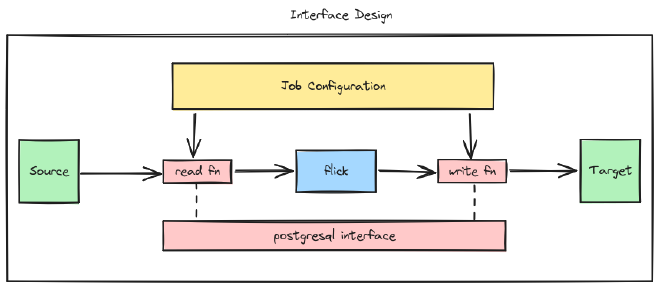
Thus, having a single interface be reused for various kinds of operations.
Moving Forward #
I only did realize after a few days of making this post as to how hectic college schedules could be. I’ll still go ahead and post this despite it being incomplete. Perhaps I’ll pick this back up once more someday.
-
While attempting to install sqlx, I found myself stuck in a scenario where I didn’t know which TLS crate to go with. sqlx supports
rustlsas well asnative-tls. Since it’s better to do some research before installing the library in my project, I looked a little into it. Since we do wish to eventually parallelize our framework, creating different data flows with specific r/w handling is a requirement. This property of being able to split streams is only available onrustls. Thus, we decided to go with the sqlx+rustls variant. But the dependencies seem to fail. So, we’re forced to pick tokio-native-tls now. ↩︎